Software Stack & Control Plane
FarmGPU’s software stack is designed to operate AI infrastructure at scale with minimal human overhead, while preserving performance, transparency, and control. Rather than relying on proprietary cloud control planes, FarmGPU builds on open-source, Linux-native primitives, extended with purpose-built systems for GPU operations. Together, these components form a unified control plane for provisioning, operating, observing, and optimizing AI clusters.TractorOS — The NeoCloud Operating System
TractorOS is FarmGPU’s minimal, immutable, container-native operating system optimized specifically for AI compute.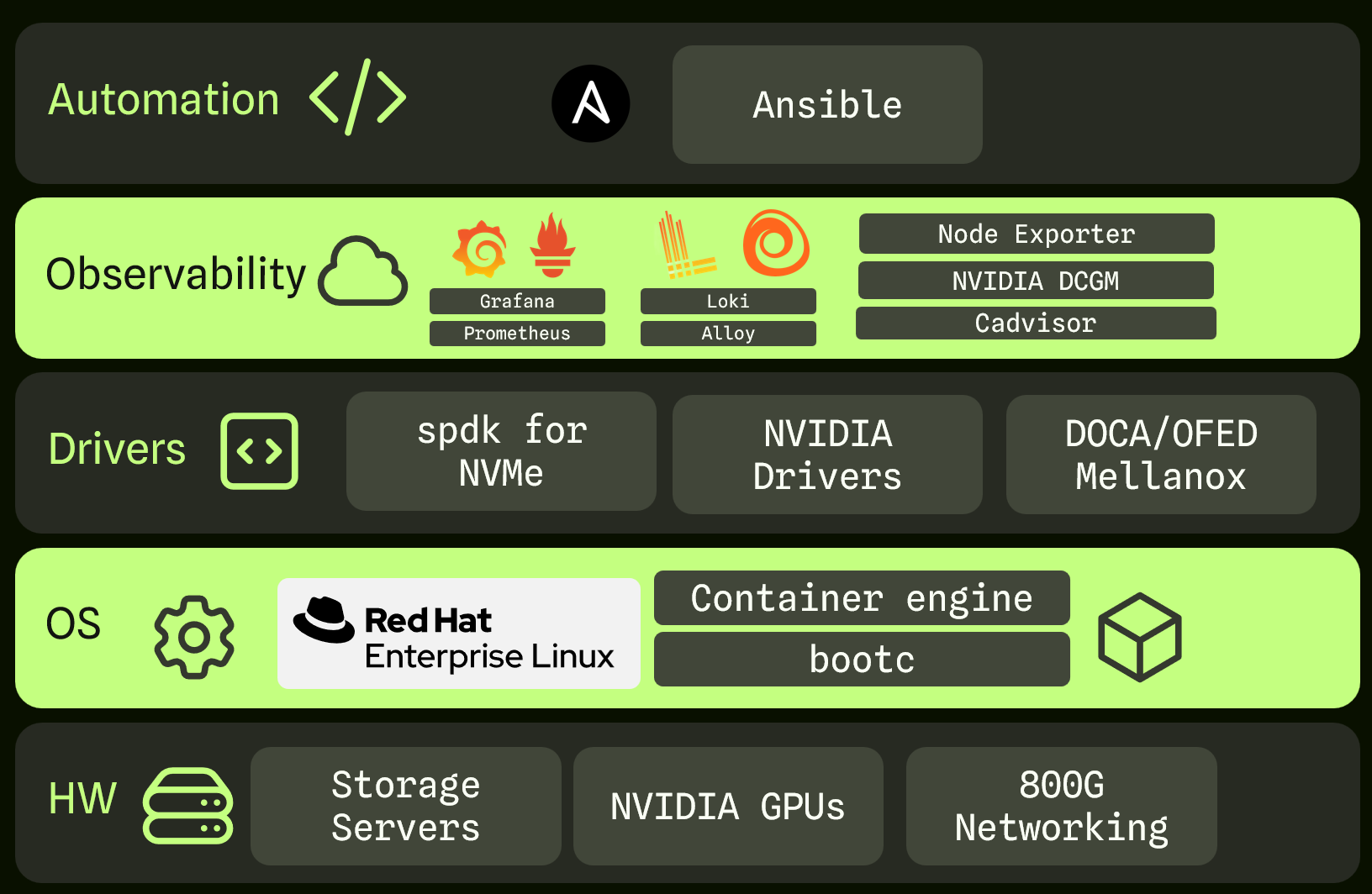
What TractorOS Does
- Provides a hardened, reproducible OS image for GPU and storage nodes
- Ships with built-in GPU, networking, and storage drivers
- Enables zero-touch provisioning and fleet-wide upgrades
- Eliminates configuration drift across clusters
Key Characteristics
- Linux-based (RHEL-derived)
- Immutable image-based updates
- Container-first runtime model
- Designed for bare metal AI infrastructure, not VMs
Homestead — Bare-Metal Provisioning & Lifecycle Management
Homestead is the entry point for every FarmGPU server.What Homestead Does
- Bare-metal provisioning via Redfish and Ansible
- Hardware discovery and inventory
- Initial OS deployment and configuration
- Support for KVM VMs and LXC containers where needed
Shepherd — System Health, Reliability & Diagnostics
Shepherd is FarmGPU’s system health evaluation platform, designed to make AI infrastructure observable, debuggable, and predictable.What Shepherd Monitors
- GPU health and performance (via NVIDIA DCGM)
- Network health and packet loss
- Storage latency and throughput
- Host-level metrics and anomalies
Advanced Capabilities
- Predictive failure detection
- Agentic diagnostics and root-cause analysis
- Automated incident summaries and reports
- Integration with observability tools (Grafana, Prometheus, Loki, Alloy)
Silo — Storage Infrastructure & Benchmarking
Silo is FarmGPU’s storage evaluation and optimization platform.What Silo Does
- Deploys and benchmarks block, file, and object storage systems
- Evaluates storage performance under AI workloads
- Performs hardware discovery and tuning
- Validates storage configurations before production rollout
Haystack — AI Workload Profiling & Optimization
Haystack provides workload-level visibility into how AI jobs consume infrastructure.What Haystack Measures
- GPU utilization by workload
- Storage I/O patterns
- Network usage and contention
- Differences between training, fine-tuning, and inference jobs
- Per-workload optimization
- Capacity planning based on real usage
- Improved scheduling and cost efficiency
- Better matching of workloads to hardware profiles
Automation, Observability & Drivers (Underlying Stack)
Across all systems, FarmGPU standardizes on proven, open tooling:Automation
- Ansible for configuration and orchestration
Observability
- Grafana
- Prometheus
- Loki
- Alloy
- Node Exporter
- NVIDIA DCGM
- cAdvisor
Drivers & Acceleration
- NVIDIA GPU drivers
- SPDK for NVMe
- NVIDIA DOCA / OFED for networking and DPU acceleration
Why This Software Stack Matters
FarmGPU’s software stack is not a SaaS product suite—it is operational leverage. It enables:- Faster cluster bring-up
- Higher GPU utilization
- Lower operational overhead
- Predictable performance at scale
- Rapid adoption of new hardware generations